李飛飛團隊最新論文:如何對圖像中的實體精準「配對」?
原標題:李飛飛團隊最新論文:如何對圖像中的實體精準「配對」?
編譯 | 費棋
出品 | AI科技大本營(公眾號ID:rgznai100)
【導語】近日,李飛飛的斯坦福大學視覺實驗室發布了一篇即將在 CVPR 2018上要介紹的論文 Referring Relationships(指稱關係),這篇論文主要研究的問題是給出一張圖像中實體的關係網路,從而讓 AI 迅速定位出某一主體所對應的客體,或者某一客體所對應的主體。
?
 ?
?
以下內容來自 Referring Relationships 論文,AI科技大本營摘譯:
圖像不僅僅是對象集合,每個圖像都代表一個互相關聯的關係網路。實體之間的關係具有語義意義,並能幫助觀察者區分實體的實例。例如,在一張足球比賽的圖像中,可能有多人在場,但每個人都參與著不同的關係:一個是踢球,另一個是守門。
在本文中,我們制定了利用這些「指稱關係」來消除同一類別實體之間的歧義的任務。我們引入了一種迭代模型,它將指稱關係中的兩個實體進行定位,並相互制約。我們通過建模謂語來建立關係中實體之間的循環條件,這些謂語將實體連接起來,將注意力從一個實體轉移到另一個實體。
我們證明了我們的模型不僅好於在三種數據集上實現的現有方法--- CLEVR,VRD 和 Visual Genome ---而且它還可以產生視覺上有意義的謂語變換,可以作為可解釋神經網路的一個實例。最後,我們展示了將謂語建模為注意力轉換,我們甚至可以在沒有其類別的情況下進行定位實體,從而使模型找到完全看不見的類別。
▌指稱關係任務
指稱表達可以幫助我們在日常交流中識別和定位實體。比如,我們能夠指出「踢球人」來區分「守門員」(圖 1)。在這些例子中,我們都可以根據他們與其它實體的關係來區分這兩人。 當一個人射門時,另一個人守門。 最終的目標是建立計算模型,以識別其他人所指的實體。
?
 ?
?
圖1:指稱關係通過使用實體間的相對關係來消除同一類別實例之間的歧義。給出這種關係之後,這項任務需要我們的模型通過理解謂語來正確識別圖像中的踢球人。
指稱關係任務的結構化關係輸入允許我們評估如何明確地識別圖像中同一類別的實體。我們在包含視覺關係的三個視覺數據集上評估我們的模型 2:CLEVR,VRD 和 Visual Genome 。這些數據集中 33%、60.3% 和 61% 的關係是指不明確的實體,也即指具有相同類別的多個實例的實體。我們擴展了模型,使用場景圖的關係來執行注意力掃視。最後,我們證明,在沒有主體或客體的情況下,我們的模型仍然可以在實體之間消除歧義,同時也可以定位以前從未見過的新類別。
▌指稱關係模型
我們的目標是通過對指稱關係的實體進行定位,從而使用輸入的指稱關係來消除圖像中的實體歧義。 形式上而言,輸入是具有指稱關係的圖像 I,R = <S - P - O>,它們分別是主體,謂語和對象類別。 預計這個模型可以定位主體和客體。
▌模型設計
我們設計了一個迭代模型,學習如何在視覺關係中使用謂語來操作注意力轉移,這受到了心理學中移動聚光理論的啟發。給出足球的初始估值後,它會學習踢球的人必須在哪裡。同樣,如果對人進行估值,它將會學習確定球的位置。通過在這些估值之間進行迭代,我們的模型能夠專註於正確實例,並排除其它實例。
?
 ?
?
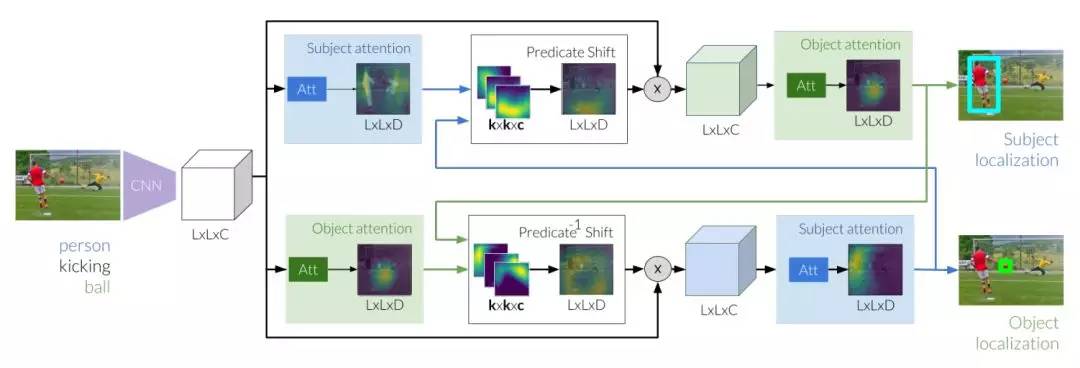
圖 2:指稱關係的推理首先要提取圖像特徵,這是用於生成主體和客體的基礎。接下來,這些估值可以用來執行轉換注意力,注意力使用了從主體到我們所期望客體位置的謂語。在對客體的新估值進行細化的同時,我們通過關注轉換區域來修改圖像特徵。同時,我們研究了從初始客體到主體的反向移位。通過兩個預測移位模塊迭代地在主體和對象之間傳遞消息,可以最終定位這兩個實體。
▌實驗
我們在跨三個數據集的指稱關係中評估模型性能來進行實驗操作,其中每個數據集提供了一組獨特的特徵來補充我們的實驗。 接下來,我們評估在輸入指稱關係中缺少其中一個實體的情況下如何改進模型。 最後,通過展示模型如何模塊化並用於場景圖注意力掃視來結束實驗。
以下是我們在 CLEVR、VRD 和 Visual Genome 上的評估結果。 我們分別標出了對主題和對象定位的 Mean IoU 和 KL 分歧:

在三種測試條件下缺少實體的指稱關係結果:

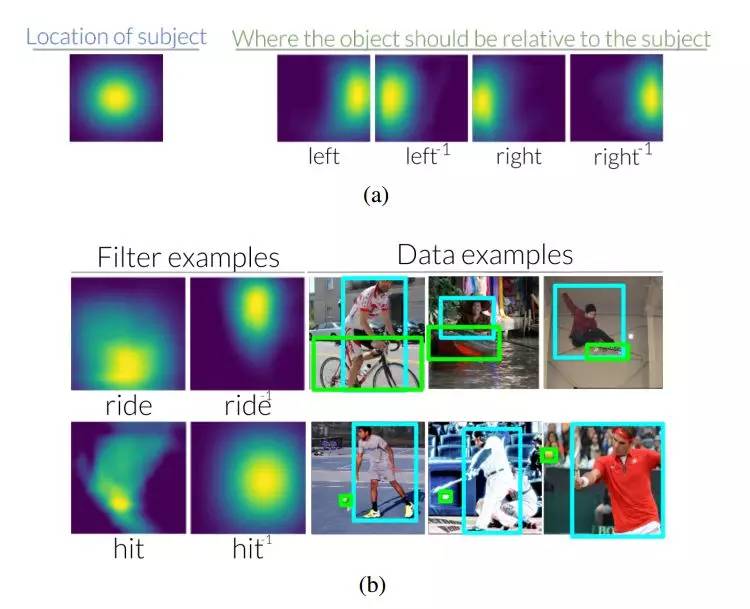
圖 3:(a)相對於圖像中的主體,當使用<subject - left - of object>關係來查找客體時,左邊的謂語會把注意力轉移到右邊。相反,當使用物體找到主體時,左側的逆謂語會將注意力轉移到左側。在輔助材料中,我們可視化了 70 個 VRD、6 個 CLEVR 和 70 個 Visual Genome 的謂語和逆謂語轉化(b)我們還看到,在查看用於了解它們的數據集時,這些轉換是直觀的。
?
 ?
?
圖 4:這是 CLEVR 和 Visual Genome 數據集的注意力轉移如何跨越多次迭代的示例。在第一次迭代時,模型僅接收試圖找到以及嘗試定位這些類別中所有實例的實體信息。在後面的迭代中,我們看到謂語轉換注意力,這可以讓我們的模型消除相同類別的不同實例之間的歧義。
?
 ?
?
圖 5:我們可以將我們的模型分解成其注意力和轉換模塊,並將它們堆疊起來作為場景圖的節點。 在這裡,我們演示了如何使用模型從一個節點(手機)開始,並使用指稱關係來通過場景圖連接節點,並在短語<拿電話的人旁邊有人身穿夾克>中定位實體。 第二個例子是關於<在戴帽子的人的右邊有個人一張桌子前>中的實體。
▌結論
我們介紹了指稱關係的目的,其中我們的模型利用視覺關係來消除了同一類別實例之間的歧義。我們的模型學習去迭代地使用謂語作為一種關係里,兩個實體之間的注意力轉換。它通過分別對主體和客體的先前位置進行預測,來更新其關於主體和客體的位置信息。我們展示了 CLEVR,VRD 和 Visual Genome 數據集的改進,證明了我們的模型產生了可解釋的謂語轉換,使我們能夠驗證模型實際上是在學習轉移注意力。通過依賴部分指稱關係以及如何將其擴展到場景圖上執行注意力掃視,我們甚至展示了如何使用我們的模型來定位完全看不見的類別。指稱關係的改進可能為視覺演算法探測未見的實體鋪路,並學習如何增強對視覺世界的理解。
相關代碼:
https://github.com/StanfordVL/ReferringRelationships
論文鏈接:
https://arxiv.org/pdf/1803.10362.pdf
作者:Ranjay Krishna , Ines Chami, Michael Bernstein, Li Fei-Fei
原文鏈接:
https://cs.stanford.edu/people/ranjaykrishna/referringrelationships/index.html


※英偉達發布史上最強GPU,卻叫停了自動駕駛車路測
※李彥宏說自動駕駛比人更安全,還認為中國用戶更願意放棄隱私
TAG:AI科技大本營 |