從AlexNet到MobileNet,帶你入門深度神經網路
原標題:從AlexNet到MobileNet,帶你入門深度神經網路
哈爾濱工業大學的沈俊楠分享了典型模式-深度神經網路入門。本文詳細介紹了關於深度神經網路的發展歷程,並詳細介紹了各個階段模型的結構及特點。
以下是精彩視頻內容整理:
問題引出
學習知識從問題引出入手是一個很好的方法,所以本文將可以圍繞下面三個問題來展開:
1.DNN和CNN有什麼不同?有什麼關係?如何定義?
2.為什麼DNN現在這麼火,它經歷怎麼一個發展歷程?
3.DNN的結構很複雜,怎麼能實際入門試一下呢?
本文思維導圖如下:
發展歷程
DNN-定義和概念
在卷積神經網路中,卷積操作和池化操作有機的堆疊在一起,一起組成了CNN的主幹。同樣是受到獼猴視網膜與視覺皮層之間多層網路的啟發,深度神經網路架構架構應運而生,且取得了良好的性能。可以說,DNN其實是一種架構,是指深度超過幾個相似層的神經網路結構,一般能夠達到幾十層,或者由一些複雜的模塊組成。
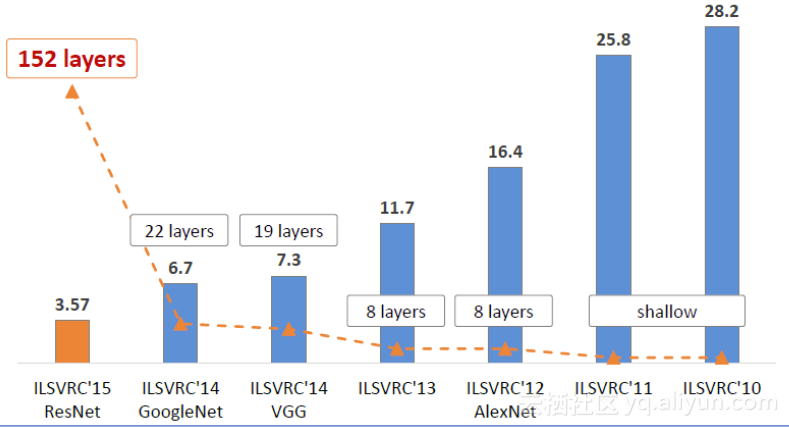
ILSVRC(ImageNet大規模視覺識別挑戰賽)每年都不斷被深度學習刷榜,隨著模型變得越來越深,Top-5的錯誤率也越來越低,目前降低到了3.5%附近,而人類在ImageNet數據集合上的辨識錯誤率大概在5.1%,也就是目前的深度學習模型識別能力已經超過了人類。
從AlexNet到MobileNet
Alexnet
AlexNet是首次把卷積神經網路引入計算機視覺領域並取得突破性成績的模型。
AlexNet有Alex Krizhevsky、llya Sutskever、Geoff Hinton提出,獲得了ILSVRC 2012年的冠軍,再top-5項目中錯誤率僅僅15.3%,相對於使用傳統方法的亞軍26.2%的成績優良重大突破。相比之前的LeNet,AlexNet通過堆疊卷積層使得模型更深更寬,同時藉助GPU使得訓練再可接受的時間範圍內得到結果,推動了卷積神經網路甚至是深度學習的發展。
下面是AlexNet的架構:
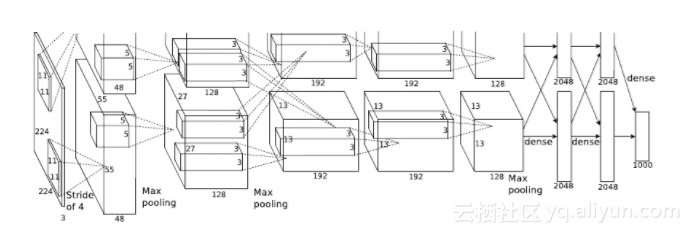
AlexNet的特點有:
1.藉助擁有1500萬標籤、22000分類的ImageNet數據集來訓練模型,接近真實世界中的複雜場景。
2.使用更深更寬的CNN來提高學習容量。
3.靈活運用ReLU作為激活函數,相對Sigmoid大幅度提高了訓練速度。
4.使用多塊GPU提高模型的容量。
5.通過LRN引入神經元之間的競爭以幫助泛化,提高模型性能。
6.通過Dropout隨機忽略部分神經元,避免過擬合。
7.通過縮放、翻轉、切割等數據增強方式避免過擬合。
以上為典型的深度神經網路運用的方法。
AlexNet在研發的時候,使用的GTX580僅有3GB的顯存,所以創造性的把模型拆解在兩張顯卡中,架構如下:
1.第一層是卷積層,針對224x224x3的輸入圖片進行卷積操作,參數為:卷積核11x11x3,數量96,步長4,LRN正態化後進行2x2的最大池化。
2.第二層是卷積層,僅與同一個GPU內的第一層輸出進行卷積,參數為:卷積核5x5x48,疏朗256,LRN正態化後進行2x2的最大池化。
3.第三層是卷積層,與第二層所有輸出進行卷積,參數為:3x3x256,數量384.
4.第四層是卷積層,僅與同一個GPU內的第三層輸出進行卷積,參數為:卷積核3x3x192,數量384。
5.第五層是卷積層,僅與同一個GPU內的第三層輸出進行卷積,參數為:卷積核3x3x192,數量256,進行2x2的最大池化。
6.第六層是全連接層,4096個神經元。
7.第七層是全連接層,4096個神經元。
8.第八層是全連接層,代表1000個分類的SoftMax。
VGGNet
VGGNet是Oxford的Visual Geometry Group提出的CNN模型,獲得了ILSVRC 2014年定位比賽以25.3%錯誤率獲得冠軍,分類比賽僅次於GoogLeNet,top-5的錯誤率為7.32%。
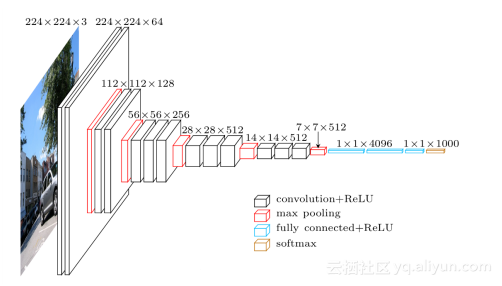
VGGNet和GooLeNet分別獨立採用了更深的網路結果,但是在設計上各有千秋。VGGNet繼承了AlexNet的設計,但是做了更多的優化:
1.更深的網路,常用的有16層和9層,取得良好性能。
2.更簡單,僅僅使用了3x3卷積核以及2x2最大池化,探索了深度與性能之間的關係。
3.收到Network in Network的影響,VGGNet的某些模型也用到了1x1卷積核。
4.採用多塊GPU並行訓練。
5.由於效果不明顯,放棄了Local Response Normailzation的使用。
網路結構大致如下:
在深度學習中,我們經常需要用到一些技巧,比如將圖片進行去中心化、旋轉、水平位移、垂直位移、水平翻轉等,通過數據增強(Data Augmentation)以減少過擬合。
ResNet
ResNet(Residual Neural Network)由微軟亞洲研究院的Kaiming He等提出,通過使用Residual Unit成功訓練152層深的神經網路,在ILSVRC2015比賽中獲得了冠軍,top-5錯誤率為3.57%,同時參數量卻比VGGNet低很多。
ResNet的靈感出自於這個問題:之前的研究證明了深度對模型性能至關重要,但隨著深度的增加,準確度反而出現衰減。令人意外的是,衰減不是來自過擬合,因為訓練集上的準確度下降了。極端情況下,假設追加的層都是等價映射,起碼不應該帶來訓練集上的誤差上升。解決方案是引入殘差:某層網路的輸入是x,期望輸出是H(x),如果我們直接把輸入x傳到輸出作為等價映射,而中間的非線性層就是F(x)=H(x)-x作為殘差。我們猜測優化殘差映射要比優化原先的映射要簡單,極端情況下把殘差F(x)壓縮為0即可。如圖所示:
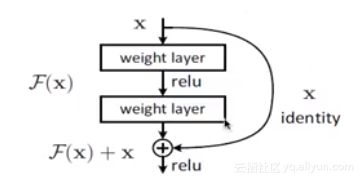
以上就是ResNet的殘差單元。殘差單元的好處是反響傳播的時候,梯度可以直接傳遞給上一層,有效率低梯度消失從而可以支撐更深的網路。同時,ResNet也運用了Batch Normalization,殘差單元將比以前更容易訓練且泛化性更好。
GoogLeNet
GoogLeNet是由Christian Szegedy等提出,主要思路是使用更深的網路取得更好的性能,同時通過優化來減少計算的損耗。
GoogLeNet的模型為Network in Network。AlexNet中卷積層用線性卷積核對圖像進行內積運算,在每個局部輸出後面跟著一個非線性的激活函數,最終得到的叫做特徵函數。而這種卷積核是一種廣義線性模型,進行特徵提取時隱含地假設了特徵是線性可分的,可實際問題往往不是這樣的。為了解決這個問題,Network in Network提出了使用多層感知機來實現非線性的卷積,實際相當於插入1x1卷積同時保持特徵圖像大小不變。
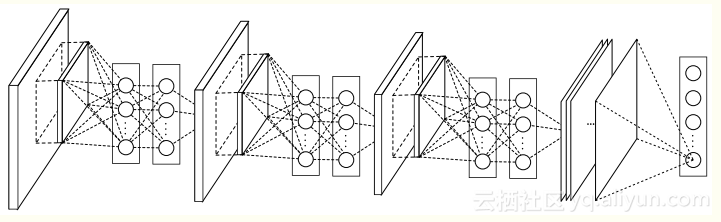
使用1x1卷積的好處有:通過非線性變化增加本地特徵抽象能力,避免全連接層以降低過擬合,降低維度,只需要更少的參數就可以。Network in Network從某種意義上證實了,更深的網路性能更好。
GoogLenet把inception堆疊起來,通過稀疏的網路來建立更深的網路,在確保模型性能的同時,控制了計算量,從而更適合在資源有限的場景下進行預測。
MobileNet
傳統的CNN模型往往專註於性能,但是在手機和嵌入式應用場景中缺乏可行性。針對這個問題,Google提出了MobileNet這一新模型架構。
MobileNet時小尺寸但是高性能的CNN模型,幫助用戶在移動設備或者嵌入式設備上實現計算機視覺,而無需藉助雲端的計算力。隨著移動設備計算力的日益增長,MobileNet可以幫助AI技術載入到移動設備中。
MobileNet有以下特性:藉助深度方向可分離卷積來降低參數個數和計算複雜度;引入寬都和解析度兩個全局超參數,可以再延遲和準確性之間找到平衡點,適合手機和嵌入式應用;擁有頗具競爭力的性能,在ImageNet分類等任務得到驗證;在物體檢測、細粒度識別、人臉屬性和大規模地理地位等手機應用中具備可行性。
理解實現-VGGNET風格遷移
風格遷移是深度學習眾多應用中非常有趣的一種,我們可以使用這種方法把一張圖片的風格「遷移」到另一張圖片上生成一張新的圖片。
深度學習在計算機視覺領域應用尤為明顯,圖像分類、識別、定位、超解析度、轉換、遷移、描述等等都已經可以使用深度學習技術實現。其背後的技術可以一言以蔽之:深度卷積神經網路具有超強的圖像特徵提取能力。
其中,風格遷移演算法的成功,其主要基於兩點:1.兩張圖像經過預訓練好的分類網路,著提取出的高維特徵之間的歇氏距離越小,則這兩張圖象內容越相似。2.兩張圖像經過預訓練好的分類網路,著提取出的低維特在樹枝上基本相等,則這兩張圖像風格越相似。基於這兩點,就可以設計合適的損失函數優化網路。
對於深度網路來講,深度卷積分類網路具有良好的特徵提取能力,不同層提取的特徵具有不同的含義,每一個訓練好的網路都可以視為是一個良好的特徵提取器,另外,深度網路有一層層的非線性函數組成,可以視為時複雜的多元非線性函數,此函數完成輸入圖像到輸出的映射。因此,萬千可以使用訓練好的深度網路作為一個損失函數計算器。
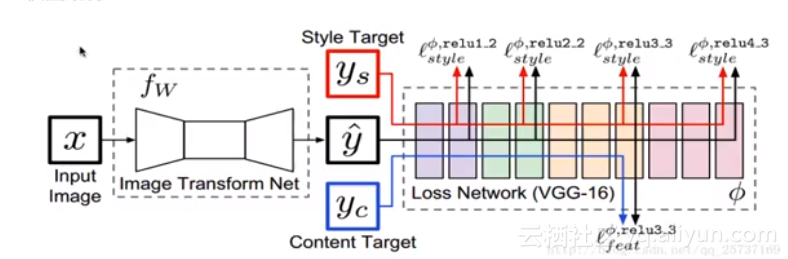
模型結構如圖所示,網路框架分類兩部分,其一部分時圖像轉換網路T(Image transform net)和預訓練好的損失計算網路VGG-16,圖像轉換網路T以內容圖像x為輸入,輸出風格遷移後的圖像y,隨後內容圖像yc,風格圖像ys,以及y』輸入vgg-16計算特徵。
在此次深度神經網路中參數損失函數分為兩部分,對於最終圖像y』,一本分是內容,一本分是風格。損失內容:
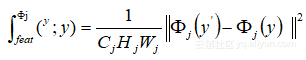
,其中代表深度卷積網路VGG-16感知損失:
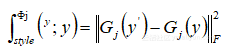
,其中G是Gram矩陣,計算過程為:
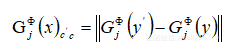
總損失定計算方式:
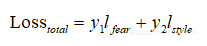
本文作者:wanwlxmmd
本文為雲棲社區原創內容,未經允許不得轉載。


TAG:阿里云云棲社區 |