剖析Hadoop和Spark的Shuffle過程差異
一、前言
對於基於MapReduce編程範式的分散式計算來說,本質上而言,就是在計算數據的交、並、差、聚合、排序等過程。而分散式計算分而治之的思想,讓每個節點只計算部分數據,也就是只處理一個分片,那麼要想求得某個key對應的全量數據,那就必須把相同key的數據彙集到同一個Reduce任務節點來處理,那麼Mapreduce範式定義了一個叫做Shuffle的過程來實現這個效果。
二、編寫本文的目的
本文旨在剖析Hadoop和Spark的Shuffle過程,並對比兩者Shuffle的差異。
三、Hadoop的Shuffle過程
Shuffle描述的是數據從Map端到Reduce端的過程,大致分為排序(sort)、溢寫(spill)、合併(merge)、拉取拷貝(Copy)、合併排序(merge sort)這幾個過程,大體流程如下:
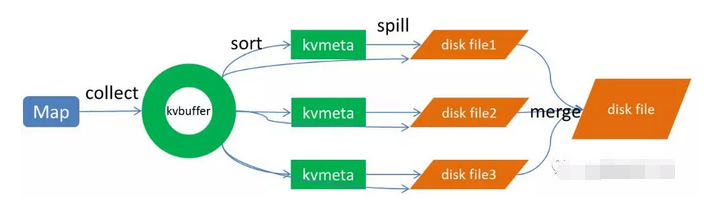
上圖的Map的輸出的文件被分片為紅綠藍三個分片,這個分片的就是根據Key為條件來分片的,分片演算法可以自己實現,例如Hash、Range等,最終Reduce任務只拉取對應顏色的數據來進行處理,就實現把相同的Key拉取到相同的Reduce節點處理的功能。下面分開來說Shuffle的的各個過程。
Map端做了下圖所示的操作:
1、Map端sort
Map端的輸出數據,先寫環形緩存區kvbuffer,當環形緩衝區到達一個閥值(可以通過配置文件設置,默認80),便要開始溢寫,但溢寫之前會有一個sort操作,這個sort操作先把Kvbuffer中的數據按照partition值和key兩個關鍵字來排序,移動的只是索引數據,排序結果是Kvmeta中數據按照partition為單位聚集在一起,同一partition內的按照key有序。
2、spill(溢寫)
當排序完成,便開始把數據刷到磁碟,刷磁碟的過程以分區為單位,一個分區寫完,寫下一個分區,分區內數據有序,最終實際上會多次溢寫,然後生成多個文件
3、merge(合併)
spill會生成多個小文件,對於Reduce端拉取數據是相當低效的,那麼這時候就有了merge的過程,合併的過程也是同分片的合併成一個片段(segment),最終所有的segment組裝成一個最終文件,那麼合併過程就完成了,如下圖所示

至此,Map的操作就已經完成,Reduce端操作即將登場
Reduce操作
總體過程如下圖的紅框處:
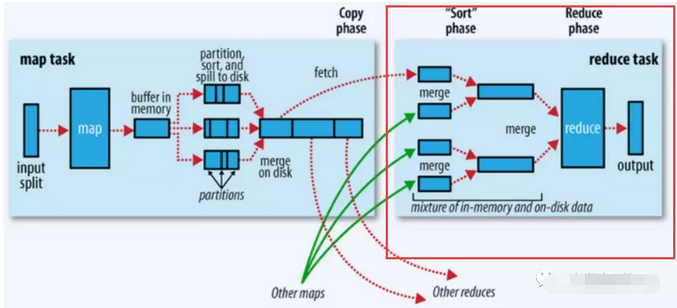
1、拉取拷貝(fetch copy)
Reduce任務通過向各個Map任務拉取對應分片。這個過程都是以Http協議完成,每個Map節點都會啟動一個常駐的HTTP server服務,Reduce節點會請求這個Http Server拉取數據,這個過程完全通過網路傳輸,所以是一個非常重量級的操作。
2、合併排序
Reduce端,拉取到各個Map節點對應分片的數據之後,會進行再次排序,排序完成,結果丟給Reduce函數進行計算。
四、總結
至此整個shuffle過程完成,最後總結幾點:
1、shuffle過程就是為了對key進行全局聚合2、排序操作伴隨著整個shuffle過程,所以Hadoop的shuffle是sort-based的
Spark shuffle相對來說更簡單,因為不要求全局有序,所以沒有那麼多排序合併的操作。Spark shuffle分為write和read兩個過程。我們先來看shuffle write。
一、shuffle write
shuffle write的處理邏輯會放到該ShuffleMapStage的最後(因為spark以shuffle發生與否來劃分stage,也就是寬依賴),final RDD的每一條記錄都會寫到對應的分區緩存區bucket,如下圖所示:

說明:
1、上圖有2個CPU,可以同時運行兩個ShuffleMapTask
2、每個task將寫一個buket緩衝區,緩衝區的數量和reduce任務的數量相等
3、 每個buket緩衝區會生成一個對應ShuffleBlockFile
4、ShuffleMapTask 如何決定數據被寫到哪個緩衝區呢?這個就是跟partition演算法有關係,這個分區演算法可以是hash的,也可以是range的
5、最終產生的ShuffleBlockFile會有多少呢?就是ShuffleMapTask 數量乘以reduce的數量,這個是非常巨大的
那麼有沒有辦法解決生成文件過多的問題呢?有,開啟FileConsolidation即可,開啟FileConsolidation之後的shuffle過程如下:

在同一核CPU執行先後執行的ShuffleMapTask可以共用一個bucket緩衝區,然後寫到同一份ShuffleFile里去,上圖所示的ShuffleFile實際上是用多個ShuffleBlock構成,那麼,那麼每個worker最終生成的文件數量,變成了cpu核數乘以reduce任務的數量,大大縮減了文件量。
二、Shuffle read
Shuffle write過程將數據分片寫到對應的分片文件,這時候萬事具備,只差去拉取對應的數據過來計算了。
那麼Shuffle Read發送的時機是什麼?是要等所有ShuffleMapTask執行完,再去fetch數據嗎?理論上,只要有一個 ShuffleMapTask執行完,就可以開始fetch數據了,實際上,spark必須等到父stage執行完,才能執行子stage,所以,必須等到所有 ShuffleMapTask執行完畢,才去fetch數據。fetch過來的數據,先存入一個Buffer緩衝區,所以這裡一次性fetch的FileSegment不能太大,當然如果fetch過來的數據大於每一個閥值,也是會spill到磁碟的。
fetch的過程過來一個buffer的數據,就可以開始聚合了,這裡就遇到一個問題,每次fetch部分數據,怎麼能實現全局聚合呢?以word count的reduceByKey(《Spark RDD操作之ReduceByKey 》)為例,假設單詞hello有十個,但是一次fetch只拉取了2個,那麼怎麼全局聚合呢?Spark的做法是用HashMap,聚合操作實際上是map.put(key,map.get(key) 1),將map中的聚合過的數據get出來相加,然後put回去,等到所有數據fetch完,也就完成了全局聚合。
三、總結
Hadoop的MapReduce Shuffle和Spark Shuffle差別總結如下:
1、Hadoop的有一個Map完成,Reduce便可以去fetch數據了,不必等到所有Map任務完成,而Spark的必須等到父stage完成,也就是父stage的map操作全部完成才能去fetch數據。
2、Hadoop的Shuffle是sort-base的,那麼不管是Map的輸出,還是Reduce的輸出,都是partion內有序的,而spark不要求這一點。
3、Hadoop的Reduce要等到fetch完全部數據,才將數據傳入reduce函數進行聚合,而spark是一邊fetch一邊聚合。


※try catch對Spring事務的影響
※關於Kafka日誌留存策略的討論
TAG:千鋒JAVA開發學院 |